DataLad provides a platform for managing and uniformly accessing data resources. It also captures basic provenance information about data results within Git repository commits. However, discovering DataLad datasets or Git repositories that DataLad has operated on can be challenging. They can be shared anywhere online, including popular Git hosting platforms, such as GitHub, generic file hosting platforms such as OSF, neuroscience platforms, such as GIN, or they can even be available only within the internal network of an organization or just one particular server. We built DataLad-Registry to address some of the problems in locating datasets and finding useful information about them. (For convenience, we will use the term “dataset”, for the rest of this blog, to refer to a DataLad dataset or a Git repo that has been “touched” by the datalad run command, i.e. one that has “DATALAD RUNCMD” in a commit message.)
In this post, we will introduce you to DataLad-Registry both as a publicly available service and as software you can deploy yourself.
Goals and Guiding Principle
In DataLad-Registry, we aim to achieve the following goals.
- Discover online datasets
- Discover dataset reuses
- Identify forks
- Identify uses as a sub-dataset
- Make up-to-date dataset metadata available
- Enable search of datasets through their metadata
In design and implementation, we embrace automation as a guiding principle. DataLad-Registry automatically
- Registers datasets discovered by datalad-usage-dashboard, a separate project developed and maintained by our teammate, John T. Wodder II, at CON that periodically searches for datasets on GitHub, OSF, and GIN.
- Extracts metadata from the registered datasets
- Updates the state of registered datasets and the corresponding metadata1
Current State
DataLad-Registry is a publicly available service accessible at https://registry.datalad.org/. It maintains up-to-date information on an expanding collection of datasets, currently numbering over thirteen thousand, including those on datasets.datalad.org and those on GitHub and GIN2 discovered by the datalad-usage-dashboard. To facilitate the discovery and utilization of datasets, DataLad-Registry leverages the datalad-metalad extension, which equips DataLad with metadata handling capabilities. This extension enables the extraction, aggregation, filtering, and reporting of metadata from datasets, thereby enhancing their accessibility and interoperability. DataLad-Registry currently employs four metadata extractors (the first four below) from the datalad-metalad extension and one built-in metadata extractor to gather metadata from datasets:
"metalad_core": Extracts fundamental metadata, including dataset identifiers and versioning information."metalad_studyminimeta": Gathers metadata from studyminimeta YAML files, producing JSON-LD compatible descriptions of the dataset’s content."datacite_gin": Retrieves metadata adhering to the DataCite schema, particularly from datasets hosted on the G-Node Infrastructure (GIN)."bids_dataset": Extracts metadata from datasets structured according to the Brain Imaging Data Structure (BIDS) standard."dandi": Provides metadata for datasets within the DANDI archive, archive for neurophysiology data.
Overview of Registered Datasets
When you visit the DataLad Registry at https://registry.datalad.org/, you’ll be greeted by the web UI of the registry.

By default, this page shows you a list of all registered datasets in descending order of when they were last updated, and in this order, the list tells you the latest activities in the registered DataLad datasets.
The lower left corner of the web UI displays statistics of the datasets matching the current search criteria. Since there is no search query provided at this point, the datasets are all the datasets registered. If you click the “Show details” button at the bottom of the web UI, you’ll see more information.

In particular, you will see information such as how many unique DataLad datasets the registry is currently tracking, and the total number and size of the annexed files in these datasets.
Details
Every DataLad dataset has a UUID attached to it, and every clone shares the same UUID regardless where it is located. Even though a platform such as GitHub allows the tracking of “explicit clones” of a repository, the identity of the original dataset could be lost. DataLad-Registry uses this ID to allow you to find clones of a dataset and datasets using the dataset as a subdataset across all platforms (see demos in the following section).
Search functionality
A description of the search syntax in DataLad-Registry is available by clicking the “Show search query syntax” button.

Example: Simple singular word search
Let’s do a search with a query of a singular word, haxby.

This searches for the substring haxby across all the searchable fields, "url", "ds_id", "head", "head_describe", "branches", "tags", and "metadata". As you can see in the search result, the statistics at the left corner have been adjusted. Click the “Show details” button, and you will see that the result consists of 20 unique DataLad datasets with 23,278 annexed files of 448.5 GB.

Example: Finding clones of a dataset
From the search result of the search for haxby, click on the OpenNeuro dataset ds001297 by its DataLad dataset ID, 2e429bfe-8862-11e8-98ed-0242ac120010.

This will cause a search for datasets with DataLad dataset ID, 2e429bfe-8862-11e8-98ed-0242ac120010, generating a field-restricted search query of ds_id:2e429bfe-8862-11e8-98ed-0242ac120010.

Thanks to the persistence of DataLad dataset ID, we have just located all the forks of a particular DataLad datasets in DataLad-Registry.
Example: Find where dataset was used (included as a subdataset)
Let’s do a search with a query of another singular word, container.

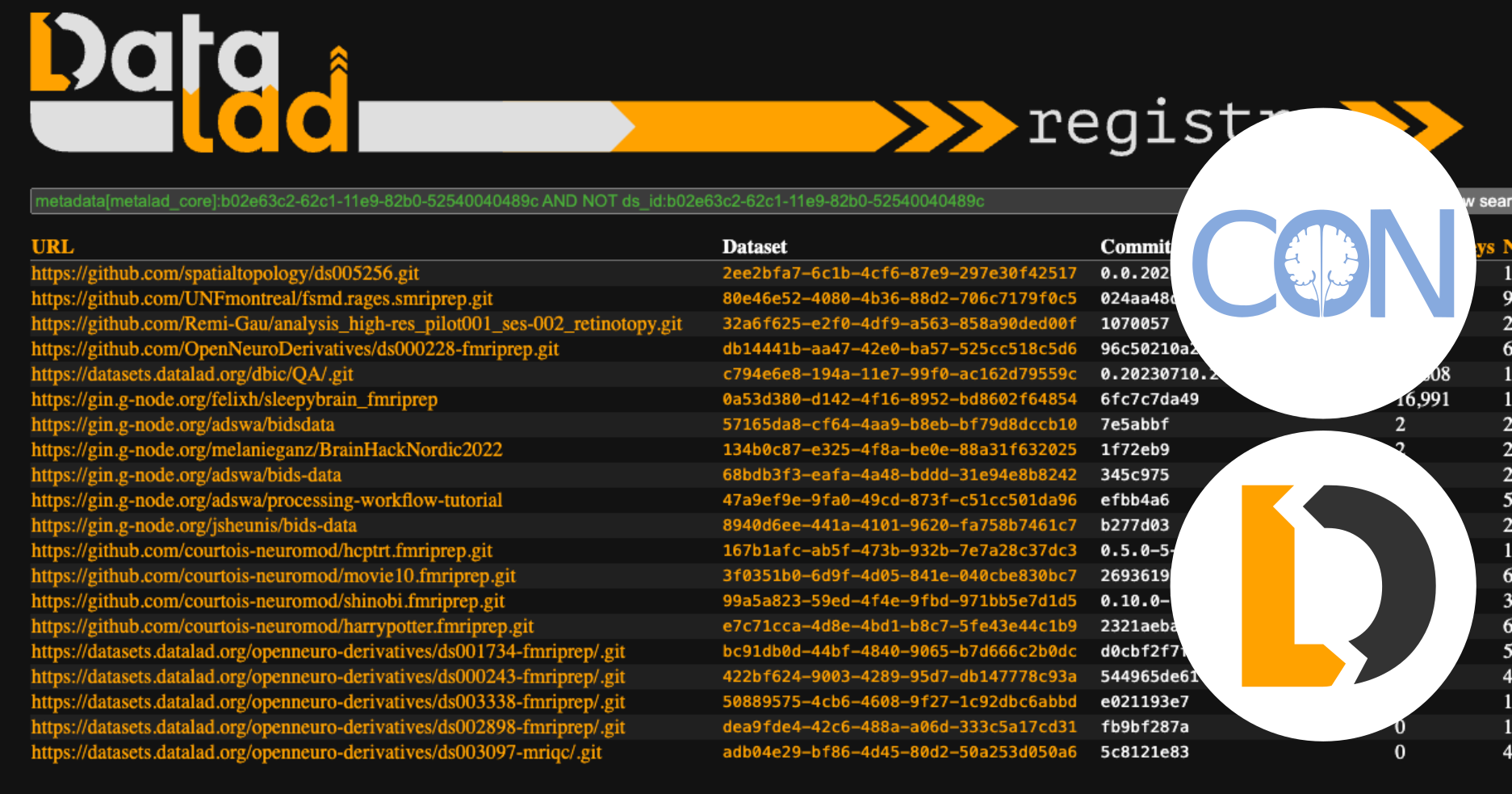
This search locates the ReproNim/containers dataset which provides “a collection of popular computational tools provided within ready to use containerized environments”. We can, of course, find all the forks of this dataset by clicking on its DataLad dataset ID, b02e63c2-62c1-11e9-82b0-52540040489c, as demonstrated in the last example. Using logical operators and restricting searchable metadata, we can locate datasets that use the ReproNim/containers dataset as a subdataset. We can do this using a search query of metadata[metalad_core]:b02e63c2-62c1-11e9-82b0-52540040489c AND NOT ds_id:b02e63c2-62c1-11e9-82b0-52540040489c.
The query, The following is the metadata extracted by the Details
metadata[metalad_core]:b02e63c2-62c1-11e9-82b0-52540040489c AND NOT ds_id:b02e63c2-62c1-11e9-82b0-52540040489c, searches for datasets with metadata extracted by the metalad_core extractor that contains the DataLad dataset ID b02e63c2-62c1-11e9-82b0-52540040489c and filters out those that possesses DataLad dataset ID of b02e63c2-62c1-11e9-82b0-52540040489c.metalad_core extractor from one of the datasets that use the ReproNim/containers dataset as a subdataset.{
"dataset_describe": "1070057",
"dataset_version": "107005775329e503cf8cad55028a4ae9fc720b2a",
"extracted_metadata": {
"@context": {
"@vocab": "http://schema.org/",
"datalad": "http://dx.datalad.org/"
},
"@graph": [
{
"@id": "ecee89b3192369e7152288468ac8c54b",
"@type": "agent",
"email": "remi_gau@hotmail.com",
"name": "Remi Gau"
},
{
"@id": "12fa27bc6e8fe98a1d855ad8d0a52076",
"@type": "agent",
"email": "66853113+pre-commit-ci[bot]@users.noreply.github.com",
"name": "pre-commit-ci[bot]"
},
{
"@id": "107005775329e503cf8cad55028a4ae9fc720b2a",
"@type": "Dataset",
"dateCreated": "2022-03-12T11:14:11+01:00",
"dateModified": "2024-10-08T09:43:26+02:00",
"distribution": [
{
"@id": "03b7452b-90e2-454c-8f1a-8c65a15d1d08"
},
{
"@id": "08930dcd-81fd-4923-8060-16eb68ec65dd"
},
{
"@id": "fd5da0d7-d8ce-4de6-9f34-cc23d9815a21"
},
{
"name": "origin",
"url": "https://github.com/Remi-Gau/analysis_high-res_pilot001_ses-002_retinotopy.git"
}
],
"hasContributor": [
{
"@id": "ecee89b3192369e7152288468ac8c54b"
},
{
"@id": "12fa27bc6e8fe98a1d855ad8d0a52076"
}
],
"hasPart": [
{
"@id": "datalad:2d02fd8c7ad744f15a39a0aadbd8a6c60703e20b",
"@type": "Dataset",
"name": "code/lib/CPP_SPM"
},
{
"@id": "datalad:b38fdf1dd75fc0fa2cf5fd2155ca4c0dd353edc5",
"@type": "Dataset",
"identifier": "datalad:b02e63c2-62c1-11e9-82b0-52540040489c",
"name": "code/pipeline"
},
{
"@id": "datalad:c6be64e3b66c7d1beae81ce800cad3c8db858701",
"@type": "Dataset",
"identifier": "datalad:9f77e14c-ff39-4a80-9121-916e5892e2b4",
"name": "inputs/raw"
},
{
"@id": "datalad:3f1acd1ca13666a49763784f9b7cea2091801f86",
"@type": "Dataset",
"identifier": "datalad:97986654-4eac-42d9-bac2-aa80c282a397",
"name": "outputs/derivatives"
}
],
"identifier": "32a6f625-e2f0-4df9-a563-858a90ded00f",
"version": "0-31-g1070057"
}
]
},
"extraction_parameter": {},
"extractor_name": "metalad_core",
"extractor_version": "1"
}
![A page showing the result of a search with the query `metadata[metalad_core]:b02e63c2-62c1-11e9-82b0-52540040489c AND NOT ds_id:b02e63c2-62c1-11e9-82b0-52540040489c`](repronim-as-subdataset.png)
Search with query metadata[metalad_core]:b02e63c2-62c1-11e9-82b0-52540040489c AND NOT ds_id:b02e63c2-62c1-11e9-82b0-52540040489c
Example: Find BIDS datasets not in OpenNeuro
Similarly, by leveraging metadata extracted by the bids_dataset metadata extractor, we can find BIDS datasets that are not currently available on OpenNeuro using the query metadata[bids_dataset]:"" AND NOT url:openneuro.
Details
metadata[bids_dataset]:"" finds all the BIDS datasets and NOT url:openneuro filters out those that are currently on OpenNeuro.
![A page showing the result of a search with the query `metadata[bids_dataset]:"" AND NOT url:openneuro`](bids-not-on-openneuro.png)
Search with query metadata[bids_dataset]:"" AND NOT url:openneuro
RESTful API
Besides the web UI, Datalad-Registry has a public facing RESTful API, and its interactive documentation is available at https://registry.datalad.org/openapi/ with three different interfaces to choose from, Swagger, ReDoc, and RapiDoc3.

Interactive API documentation interfaces.
This API has an OpenAPI V3 schema (available at https://registry.datalad.org/openapi/openapi.json). Developers can generate a client from it using OpenAPI Generator.
Supported API operations
The API currently supports the following operations.
- Registering new datasets
- Querying for datasets
- Fetching datasets and metadata by internal IDs

API endpoints shown in Swagger
Registration of new datasets is currently disabled in our public-facing instance of DataLad-Registry located at https://registry.datalad.org. However, you can choose to make that available in your own instance of DataLad-Registry should you launch one. The querying operation provided through the API supports all the features provided by the search function in the web UI. Additionally, it allows further restrictions in the query and provides an option for including metadata in search results.

A detailed view of the dataset-urls endpoint.
Deploying your own instance of DataLad Registry
If you want to benefit from DataLad-Registry for your datasets without making them publicly available on registry.datalad.org, you can deploy your own instance. A fully featured DataLad-Registry instance consists of the following service components:
- Web (Flask): Serves the web UI and API endpoints.
- DB (PostgreSQL): Stores all metadata.
- Worker (Celery worker): Executes automated tasks.
- Scheduler (Celery beat): Issues periodic tasks, such as syncing with the Datalad-Usage-Dashboard for new datasets and updating registered datasets, for the worker to execute.
- Broker (RabbitMQ): Manages task queues for Celery.
- Monitor (Flower): Provides a real-time, web-based interface to display the progress, status, and results of Celery tasks.
- Backend (Redis): Acts as a backend to store task results.
All service components are specified in a Docker Compose file, making it easy to bring up an instance of DataLad-Registry using the podman-compose command.
Read only instances
Multiple read-only DataLad-Registry instances can be set up alongside a fully featured one. Such instances consist of only the web and DB services, and they are always in sync with the fully featured instance. With read-only instances, the fully featured instance is protected from potential abuse and the workload is split. In fact, the instance you interact with at registry.datalad.org is a read-only instance.

The public instance of DataLad-Registry is available through a read-only instance.
Join/Contribute
Do you have a collection of datasets that you need to run periodic tasks on and/or make them available on the public instance of DataLad-Registry? Or do you have interesting metadata to extract? Please file an issue at https://github.com/datalad/datalad-registry/issues, and we can help you make those datasets and their metadata available through DataLad-Registry.
References
- 2024 Distribits talk:
- 💻 GitHub
- 🌐 Live instance
If a registered dataset is updated, DataLad-Registry will automatically update the local copy of the dataset and re-extract the corresponding metadata. ↩︎
DataLad-Registry currently registers all datasets found by https://github.com/datalad/datalad-usage-dashboard that reside on GitHub and GIN. OSF datasets found by https://github.com/datalad/datalad-usage-dashboard are to be added soon as well. We welcome suggestions of other archives. ↩︎
Swagger, ReDoc, and RapiDoc are tools that provide interactive documentation for the API, allowing developers to explore available endpoints easily. ↩︎